Designing for Failure: Building Resilient Distributed Systems
Failure is not an edge case — it is the default state of any distributed system. Here is how to design systems that expect and absorb failure rather than collapse under it.
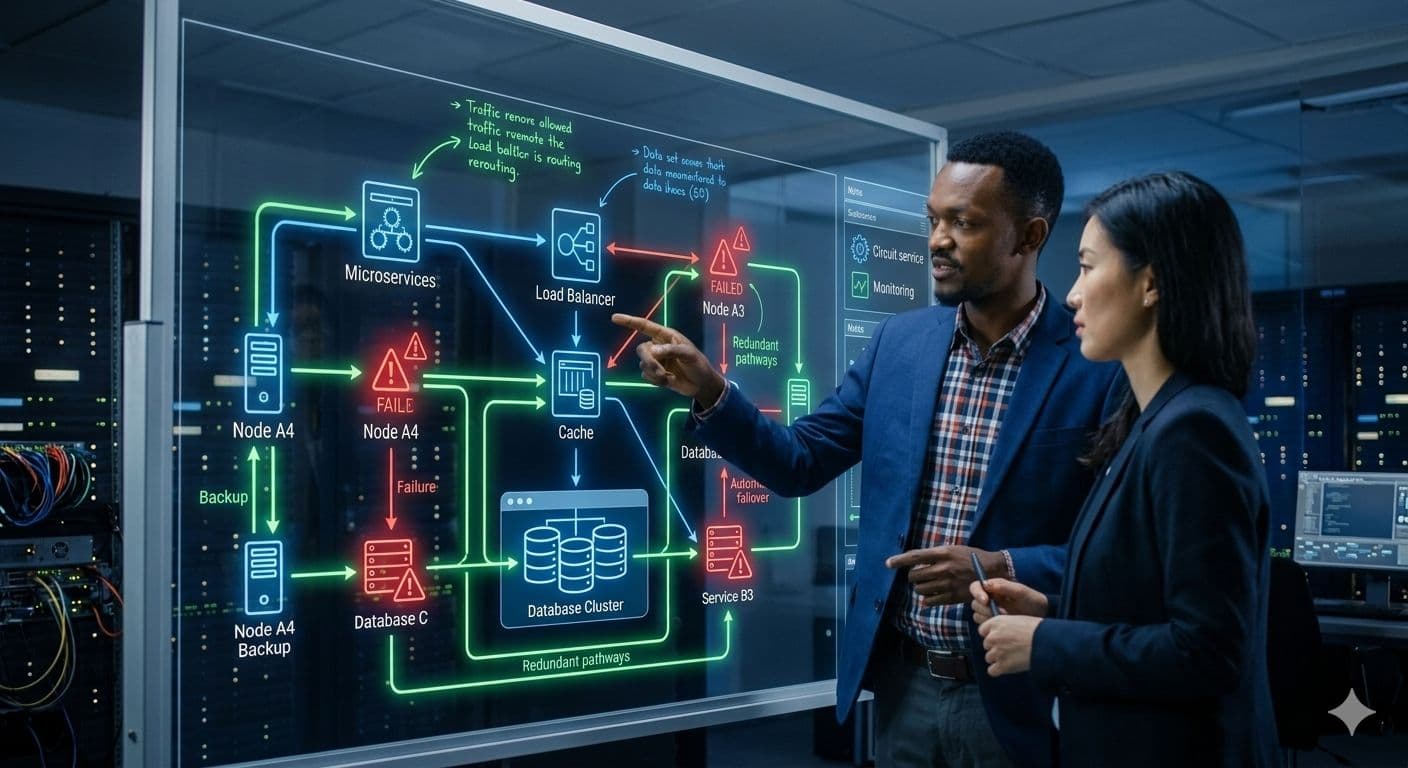
Every distributed system fails. Networks partition. Disks fill up. Downstream services time out at the worst possible moment. The engineers who build reliable systems are not the ones who prevent failure — they are the ones who design for it from the first line of code.
The Problem with Optimistic Architecture
Most systems are designed around the happy path. A request comes in, services cooperate, data is returned. This is a useful mental model for initial design, but it becomes dangerous when it is the only model. Optimistic architecture assumes that every remote call succeeds, every database is reachable, and every queue drains on schedule. In production, none of these assumptions hold consistently.
The cost of this optimism is paid in production incidents. A single slow dependency causes threads to accumulate. Thread pools exhaust. The entire service becomes unresponsive — not because of anything it did wrong, but because it did not account for the possibility of a neighbour behaving badly.
The Three Failure Modes You Must Plan For
In practice, distributed failures cluster into three categories. The first is network failures: packets dropped, latency spikes, DNS resolution delays. These are the most common and the easiest to design around with timeouts and retries. The second is service failures: a dependency crashes, deploys badly, or becomes overwhelmed. The third is data failures: corrupt records, schema drift, unexpected nulls. Each requires a different response strategy.
Circuit Breakers, Bulkheads, and Timeouts
The circuit breaker pattern stops calls to a failing dependency before they accumulate. Once a threshold of failures is reached, the circuit opens and calls fail fast. This prevents cascading failures from propagating through the system. Bulkheads isolate thread pools per dependency so that one slow service cannot exhaust the shared pool. These are not optional performance optimisations — they are survival mechanisms.
A timeout without a circuit breaker is just a slower failure. The circuit breaker is what turns a cascading outage into an isolated incident.
Designing for Observability First
Resilience without observability is guesswork. You cannot recover from what you cannot see. Every service should emit structured logs, expose metrics, and propagate distributed trace IDs across service boundaries. The goal is not just detecting that something broke — it is understanding exactly where and why, within minutes of the incident starting.
The Production Mindset
Resilient architecture is not a feature you add at the end. It is a constraint you design around from the start. That means writing failure scenarios into your design documents, running chaos experiments before launch, and treating every external call as a liability rather than a guarantee. The systems that hold under pressure are the ones built by engineers who assumed they would be under pressure.